On and off over the past year I’ve been working with Jason Baron on a design for a UI for system administrators to control processes’ and users’ usage of system resources on their systems via the relatively recently-developed (~2007) cgroups feature of the Linux kernel.
After the excitement and the fun that is the Red Hat Summit, I had some time this week to work with Jason on updating the design. Before I dive into the design process and the mockups, I think it’d be best to do a review of how cgroups work (or at least how I understand them to) so that the rest makes more sense. (And maybe I’ve got some totally incorrect assumptions about cgroups that have resulted in a flawed design, so hopefully my calling out the current understanding might make it easier for you to correct me 🙂 ).
A designer’s understanding of cgroups via diagram
So cgroups, which are sometimes referred to as containers (I think because a similar Solaris feature, zones, is sometimes called containers) can be used to slice an entire operating system into buckets, similarly to how virtual machines slice up their host system into buckets, but without having to go so far as replicating an entire set of hardware.

So this diagram kind of shows how four of the system resources that cgroups can control – CPU, memory, network, and storage I/O – could be cut into slices that are then combined into two groups – the yellow and the purple one – which make up virtual OSes. Say I gave cgroup #1 (yellow) to Sally, and cgroup #2 (purple) to Joe. Whenever Sally starts a process, you could set it to only run on the CPUs that are members of cgroup #1 (via cpuset), at whatever priority level is set for those CPUs (via cpu). It’ll only be able to use as much memory as was allocated to cgroup #1, only be able to use as much network and I/O bandwidth as cgroup #1 is able to use. When Joe starts a process, because he’s part of cgroup #2, he won’t be using the same CPUs as Sally. He may have more or less memory, I/O, and network bandwidth allocated to him.
It’s kind of / sort of like Joe and Sally are using different computers, on the same operating system. Cool, right?
Cgroups don’t have to go that deep, though. You don’t need to slice across an entire system.

You can have a cgroup that *just* deals with controlling access to the CPU. Or *just* controls memory. Or maybe only deals with two of the four (CPU, Memory, Network, I/O) resources, or just three of the four.
You can have a cgroup that *just* deals with one resource (say CPU), and that group only deals with specific processes. Or users. Or a combination thereof. (More later on that.)

Depending on the resource you’re looking to control and the cgroups module you’re using, you can configure access to that resource in different ways. I believe one of the more common ways of controlling CPU usage via cgroups is to assign ‘shares’ for various groups’ usage of the CPU (using the ‘cpu’ module.) I’m not sure what scale/units these shares are on, but they are relative to each other, so if I give group #1 a weight a 1024, and group #3 a weight of 2048, then group #3 will get scheduled for CPU time twice as much as group #1 will.
I don’t think this share system is particularly intuitive, which is still an open problem in the current draft of the UI design.
Other resources and modules let you control access in different ways. For example, the memory module lets you configure an upper bound of memory usage, I believe via providing the maximum number of bytes of memory that could be used by members of the group.
You can create and apply cgroups to processes and users on-the-fly or on a longer-term / persistent basis. Say some process is running amok and is starving other processes on your system… you can change the process’ cgroup membership on-the-fly to provide it a more limited set of system resources so that other processes on the system can run. However, this change would be temporal and may be based, for example, on a specific pid number that won’t apply if the process is restarted or the system is rebooted. If you’d like more persistent cgroup membership, you can create a set of rules (cgrules.conf). A neat simple thing you could do with cgroup rules, for example, is something mentioned by Linda Wang in her Red Hat Summit talk on cgroups; you could arrange your cgroups rules such that the sshd always gets a dedicated chunk of CPU time so that if a process runs amok on a server system, you still might be able to ssh in remotely to diagnose the problem.

It’s via these rules that you can set up persistent groups on the system. It would be kind of a pain to have to set them up every time a system is rebooted, especially the more processes and users you’re managing, and the more groups you need to create in order to manage them. You can use multiple cgroups modules (for example, cpu, cpuset, mem, net) within a single cgroup, and then write rules to place processes run by particular users and/or user groups into the cgroup, or write rules to place processes matching particular attributes into the group.
Above is a diagram demonstrating a cgroup that restricts only CPU usage for processes matching firefox-*, npviewer.bin run by users that are in the ‘guest’ group or whose usernames are ‘student1’ or ‘student2’. Kind of putting it all together, showing a single group and its resource allocation, and its associations with particular users and processes.
Who would use a UI for this, and why?
Tthe UI design mostly focuses on setting up persistent rules, and doesn’t really allow for on-the-fly cgroups rearrangement of currently-running processes and currently-logged in users. The thinking behind this is that there might be a couple of main reasons you’d be using a UI for cgroups:
- Proactive: Initial system resource allocation planning
- Reactive: In response to a complaint – ‘My processes are getting capped,’ or ‘Such-and-such process isn’t running right.’
Thinking about the way my previous experience with system administrators has typically gone, there’s sadly not usually a lot of time for proactive planning and organization – a majority of time tends to get spent on reacting to client concerns. If someone is calling you up on the phone to tell you that a process they are relying on has gone awry, it seems the most effective way to get them to stop calling you would be to change the rules to make a more persistent change to help them, rather than to just apply a change on the fly and wait for their next phone call. 🙂 So I think you’d probably prefer to change rules in reaction to a client complaint, not just do an on-the-fly change (although you could.) When you’re being proactive and initially setting up a system, I think you’d not want to do that on-the-fly at all, because you’d have to keep reapplying. It’d be better to craft a set of rules to persist on the system.
So it seems like these two main use case types – proactive resource allocation, and reactive allocation adjustments based on client feedback – are both best served by focusing on rules, so that’s why the UI design only focuses on those.
Maybe there is a case for doing the on-the-fly stuff though. It does make for some pretty awesome demos, though, like the one Bob Kozdemba gave at the Red Hat Summit last Friday, moving multiple copies of a graphics rendering tool between cgroups and vms and changing their configuration on the fly so you could visually see the affect of resource caps on the processes.) You could also use the on-the-fly configuration changes to test out a theory about how you should set the rules.
So, specifically, what kinds of problems could we imagine a user looking to solve with this interface? Our thoughts were that most likely a system administrator would find it most useful:
Under the ‘Proactive’ Category:
- I have a system running a business-critical app that sadly has a memory leak, and I want to make sure that app doesn’t screw up the other apps running on the system. I’d like to put a cap on its memory usage so when it goes down it doesn’t take the rest of the system down with it.
- I have a thin-client lab meant for the use of students in the science department, but students from other departments are allowed access via guest accounts. I’d like to make sure the guest accounts don’t block any of the science department students’ work on the server.
- I’m an administrator at an ISP and we provide virtual machines to end users in different pricing tiers. I’d like to enforce the limits set by our pricing tiers so that customers’ VMs aren’t getting more power than they are paying for and aren’t starving customers that are paying for more power.
Under the ‘Reactive’ Category:
- A student from the science department has called helpdesk to complain that his simulations don’t have very much oomph and are taking far too long to run. I need to figure out what system resource policy might apply to this user, and make modifications to his policy as needed to help him out if possible. (For example, perhaps he was previously outside of the science department and just transferred in, so he’s still running in the guest group.)
- Uh-oh, something’s gone wrong. A business critical process keeps getting OOM’ed! I need to figure out what resource allocation policy applies to it to see if there a rules that are causing the issue / that could be adjusted to get the app running consistently again.
- Our bi-weekly payroll processing application is still going full-steam ahead but it’s Monday morning, the business day is starting, and that server needs to be used for other things. Whoops, that’s never happened before, it usually finishes on Sunday. I need to see what policy applies to it, and modify our rules so that the payroll process tones things down a bit if it hasn’t finished over the weekend.
The mockups
So after a lot of sketching, crossing out, sketching, crossing out, and thinking about the above types of use cases, we thought to break up the main window in this way:
- A users tab: For when you have a specific user/group in mind you’d like to limit, or if you’ve got a specific user on the phone who you’re trying to troubleshoot with;
- A processes tab: For when you have a specific process in mind you’d like to limit, or if you’ve got someone on the phone upset about a particular process you need to help debug;
- A containers tab: For when you need to initially create your cgroups, or if you’d like to tweak the configuration of a particular group, or if you’d like to see how the processes within the group are performing.
So here’s what they look like:
The users tab

The processes tab
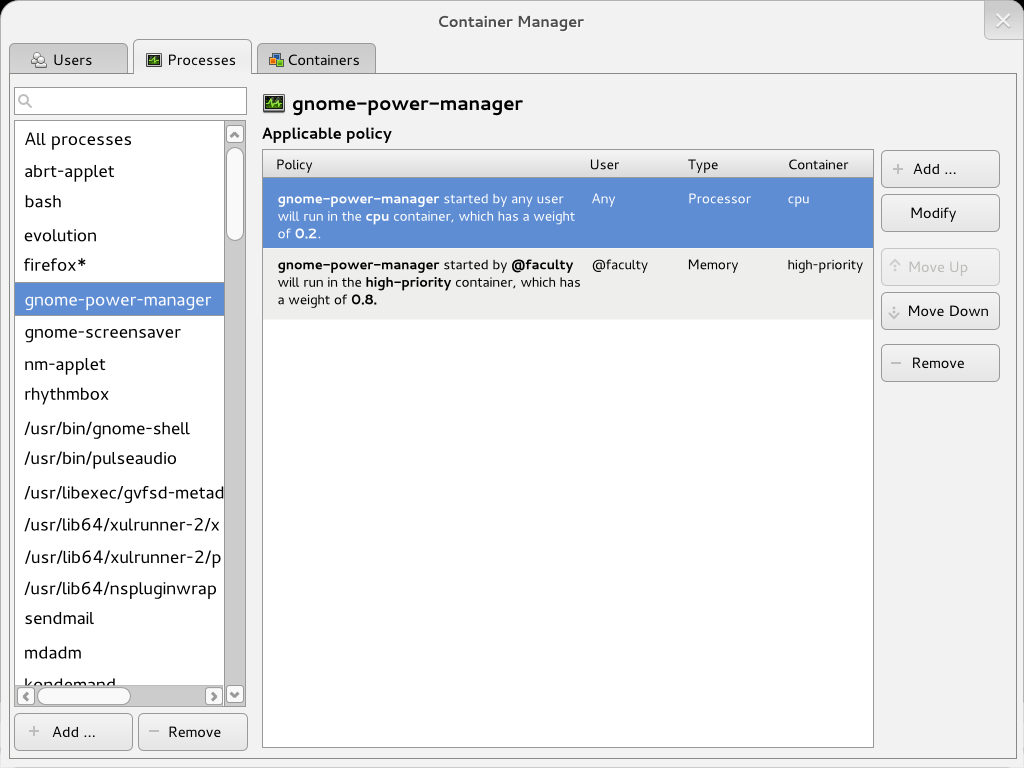
The containers tab

Some issues / further work
Here’s a bit of a braindump of where these need more work:
- So I mentioned in one of the example use cases a payroll application, that could run full steam during the weekend but had to be dialed back during the work week. Well – this UI design doesn’t account for scheduling in the rules, yet.
- There’s no mockups for the various dialogs needed for adding and modifying rules.
- It would be cool to do a mockup showing how this might integrate into the GNOME system monitor – maybe an additional filter on it?
- It would also be cool to have some kind of integration with the user accounts dialog. Maybe it’d show the policy that applied to a user and let you modify it from that dialog?
- Right now in the containers tab, we had the idea to list the containers by the resource they are managing – so groups involving cpu, cpuset, cpuacct for example would all be listed under a ‘CPU’ category. However, Jason had an idea about showing logical cgroups that span resource types – e.g., you might have a cgroup tuned for DB usage with different settings for CPU in combination with memory & I/O.
- The users and processes tab doesn’t really let you monitor resource usage per user / per process. Is that needed? Not sure.
- Units – shares vs upper limits vs… the actual numbers you’re configuring for each rule need to be fleshed out. If cpu / cpuset / cpuacct for example can be used in conjunction, how would that be shown in the UI?
- What about a mechanism to compare effective resource allocation vs actual resource usage? So you could see, ‘hey, this process is starved, maybe we should consider upping it,’ or ‘hey, this user isn’t really coming anywhere near their limits, should we dial them down?’ An earlier draft of the mockups showed graphs of each for comparison.
- (Edit: idea from Bill Nottingham) Support multiple systems in one UI over the network
The wiki page for this design (including Inkscape SVG sources) is here:
http://fedoraproject.org/wiki/Design/CGroupsUI
Feedback
Is this nuts? Does it make sense? Is this the wrong approach? Do you use cgroups? Would this be a useful tool, or does it suck?
I hope you’ll let us know.


Some comments on the UI…
1) The exposing of 'weight' as a concept is problematic, as you mentioned.
2) is '@foo' syntax for groups a common paradigm? Is it better to refer to it as 'the group'?
Honestly, I'm almost more concerned about the backend:
1) As an interface, how does this interact with systemd's use of cgroups?
2) What sort of interface does it provide to this application frontend? Would it also be useful for a remote API?
… and, in combination:
3) If so, should this UI be crafted in a way where it can manage arbitrary machines over the network? This might change the interface somewhat.
Stepping back – in what cases above is this tool the appropriate answer, and in what cases is something like tuned the appropriate answer? There seems to be a lot of overlap, and I wonder if a general tuning tool that incorporates both is the way to go.
Hi Bill,
UI
1) +1
2) It's definitely better to refer to groups as groups rather than use @!
Backend
1) Both Jason and I agreed there are particular groups it wouldn't make sense to expose, the systemd groups being an example of those.
2) I'm not sure, a good question for Jason 🙂
3) It would be good for it to support remoting as well… my thought was maybe it could follow a process similar to the virt-manager UI, where we first focused on getting the single-system use case right, then extended it to apply to multiple hypervisors over a network.
What is tuned? Do you mean tuna?
[elad@elephant ~]$ yum info tuned
Loaded plugins: langpacks, presto, refresh-packagekit
Available Packages
Name : tuned
Arch : noarch
Version : 0.2.20
Release : 1.fc15
Size : 85 k
Repo : fedora
Summary : A dynamic adaptive system tuning daemon
URL : https://fedorahosted.org/tuned/
License : GPLv2+
Description : The tuned package contains a daemon that tunes system settings
: dynamically. It does so by monitoring the usage of several system
: components periodically. Based on that information components will
: then be put into lower or higher power saving modes to adapt to
: the current usage. Currently only ethernet network and ATA
: harddisk devices are implemented.
Although tuna (the fish, not the software) is also good 🙂
Right, we have tuned for adjusting overall system performance, tuna for adjusting particular applications, and now this.
Furthermore, we have ulimits for limiting particular users and apps, and cgroups for limiting particular users and apps.
So, the question is – how do you coalesce all of these into an interface for monitoring and tuning application limits and performance? It's not an easy question, but if we want to do something Awesome, I think we need to figure out how to combine some of these similar tools into a cohesive whole.
This definitely something I'd love to see implemented, perhaps as an addition to the standard GNOME System Monitor.
It is great that you are spending so much time with programs which have traditionally been or are going to be used by power users and system administrators
Interesting ideas!
I can't call myself an expert on cgroups, but from what I've read about them, they probably aren't the right tool to use to solve many of these problems.
For example, limiting memory usage per user can be legitimately helpful, but limiting memory usage per process name is almost certainly unhelpful. This is since:
1) Process names are very simple to manipulate, so any program can be run with a name that avoids certain limitations or a name that cashes in on some bonus.
2) You can make a system vastly more inefficient by not letting it use the resources it needs when they are available. If an application wants to use 1GB of memory, it won't magically use any less if you stuff it into a memory-restricted cgroup. All that will happen is that it will either crash (and in the worse case, corrupt some user data), or it will start swapping and degrade the performance of the whole system. And, in either case, there was likely still perfectly good memory available outside of the cgroup.
Honestly, I'm worred that if these kinds of restrictions are just stuck in an easy-to-use (but also easy-to-abuse interface), then clueless admins will go "hmm — I know — I can solve all our problems by tweaking some knobs here." It should be made clear to people using the program that some resource limits may have unintended effects on the overall system performance (for another example, a cgroup which only gets an artificially small fraction of CPU time can hold locks or resources needed by other cgroups and effectively hang them).
Aside from making the program so complicated that you would have to know exactly what you're doing in order to use it, I think the only reasonable way to deal with these things is:
– Don't give people power to do too much damage with this interface
– In my opinion, per-process restrictions are too impotent to be of use. They shouldn't be exposed in the UI. The only predictable process names on the system are those started directly by the system, and resource limits for those processes should be managed not by process name but through the corresponding systemd cgroups (which would be helpful to expose in the UI).
– Avoid exposing hard limits where possible. Soft limits are more forgiving.
– If something might possibly cause damage, make sure there's some kind of warning like "This could negatively impact the whole system performance if you've set something unwisely".
Interesting stuff. A note and a couple of comments.
In Bill's comment, I think he was possibly referring to ksmtuned, the ksm "governor" which is part of the qemu-common package. Some sketchy info can be found at: http://fedoraproject.org/wiki/Features/KSM
My own thoughts:
1. I'm not a huge fan of the "wordy" descriptive entries in the Policy column of the Users and Processes tabs.
(a) The format (which is reminiscent of the Inform IDE, used for developing Infocom-style interactives in their plaintext story language) means you're forced to scan to pick out details, which is probably why
(b) most of the relevant information is redundantly duplicated in the other columns, leading to redundancy, and
(c) they make each row in the list quite tall
2. Some of this is more a general cgroups question than a UI issue, but how are inheritance and precedence handled with this system?
(a) On inheritance, does cgroups function like traditional process priority, where I can start a shell nice'd to -5 and all processes started from it will also run with -5 prio? Or do the rules always override? What happens in the case of there being no rule that applies to a given process? Say, if I don't define "all" rules for processes or users, but create a rule that governs how all gnome-terminal (or zsh?) processes run, then launch firefox from that zsh-inside-gnome-terminal?
(b) I notice you have "Move up" and "Move down" buttons in the interface, so presumably rules can be prioritized against each other. But that list is also showing a filtered view, which could have unforseen consequences if rule priority is global. For instance, say I'm user "ferd", and there are two rules showing for me: one on @users, another on @staff. If I switch those two rules' priority, does that affect ALL staff users? And if another user "mary" is also @users @staff, but her panel has four OTHER policy rules also listed, when the priority is changed on my panel how do those rules move relative to the other rules on mary's panel?
(c) When multiple rules apply to a process, but in different ways, how are they applied? If I have a rule saying all @user processes run in "slowpokes" with a cpu limit of 50%, and another saying all firefox processes run in "realtime" which is weighted 0.8, is it purely an either/or which applies, based on the rule priority? Or can both apply, since the two parameters are not mutually exclusive?
There's probably a bit more I'd like to comment on, but this is getting long already and I need to woolgather. It's an interesting approach to controlling a powerful & complex feature, though. Thanks for sharing!
Your mockups look pretty as always, but if you think real sysadmins will want to use a gui to manage their servers, then this is slightly insane. I might have missed the point slightly. If this is for general desktop use, that's another use-case. Just my opinion anyways, Thanks!
Hi James, you might find it hard to believe or as you phrased it, 'insane', but one doesn't usually create UI designs like this for fun. In fact, actual system administrators asked for a UI on top of cgroups which is why we've been looking into it in the first place. 🙂
Despite stereotypes, many "real sysadmins" *do* appreciate a decent GUI for managing stuff. They might not cover 100% of the capabilities of command line tools or hand-editing config files, but if something deals with all the common scenarios well, it can be a big time saver.
Your use of the word "Containers" makes me think of LXC. It seems like you're going for something slightly different? Maybe I misunderstood though! It would be cool if this UI integrated with LXC to show you resource usage of each running container.
Your idea is very good as representation, but basically you hit the following issues:
The first image reflects a safe and efficient structure.
The problem arises when the two begin to transmit data, synchronization occurs … linking data …
In the first figure you have a hardware level synchronization problem, the second figure you have a problem syncing groups …
In both cases there will be trouble … your article does nothing more than to say that you're smart.
Read your article again and look like a hacker … looking for bugs …
Here's a starting point, the level of structure that applies to your optimization.
I would choose only certain hardware … such as MEMORY and CPU for a CERTAIN LEVEL 😉
Optimization is a circle.
I don't understand what you are referring to. Cgroups themselves and the explanation with diagrams, or the UI mockups?
I referring about cgroups via diagram…
Hm, I'm confused then. Cgroups is a feature that's already been designed and implemented and works… I am only looking for feedback on the UI on top.
This is a great idea! One feature I'd like to see for this application is adjusting a remote system (so that you can tune your server(s) in a graphical way without having graphical tools installed on the server).
And, as a KDE user, it would be cool if this app could have a KDE front-end (Qt) as well, but that's more of a nice-to-have.
Mo, excellent post as always. I have the same LXC question as Chris, though.
I assume that the design you come up with may be influential beyond Fedora. In MeeGo, we're discussing LXC. It's possible that a lot of mobile platforms will adopt a variant of Android's "every 'app' has its own UID" where instead "every app runs in its own cgroup." I don't know what that would mean for the UI either! Integration with popular tools like ps and htop would help a lot (perhaps these changes are already underway).
As someone who has switched desktops just today, I hope that any solution won't rely too much on Gnome! I appreciate of course that you must make a particular choice to get started testing.